YoungStatS
The blog of Young Statisticians Europe (YSE)
bayesian-statistics
Linear-cost unbiased estimator for large crossed random effect models via couplings
Paolo Ceriani and Giacomo Zanella
/
2023-09-27
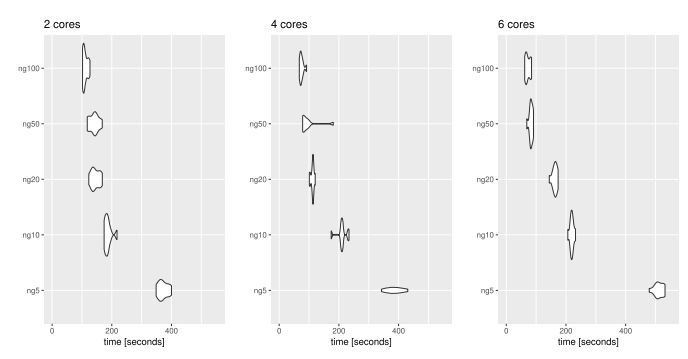
In the following we show how it is possible to obtain parallelizable, unbiased and computationally cheap estimates of Crossed random effects models with a linear cost in the number of datapoints (and paramaters) exploiting couplings. […] CREM model a continuous response variables \(Y\) as…
high-dimensional-data
Procrustes Analysis for High-Dimensional Data
Angela Andreella and Livio Finos
/
2023-03-02
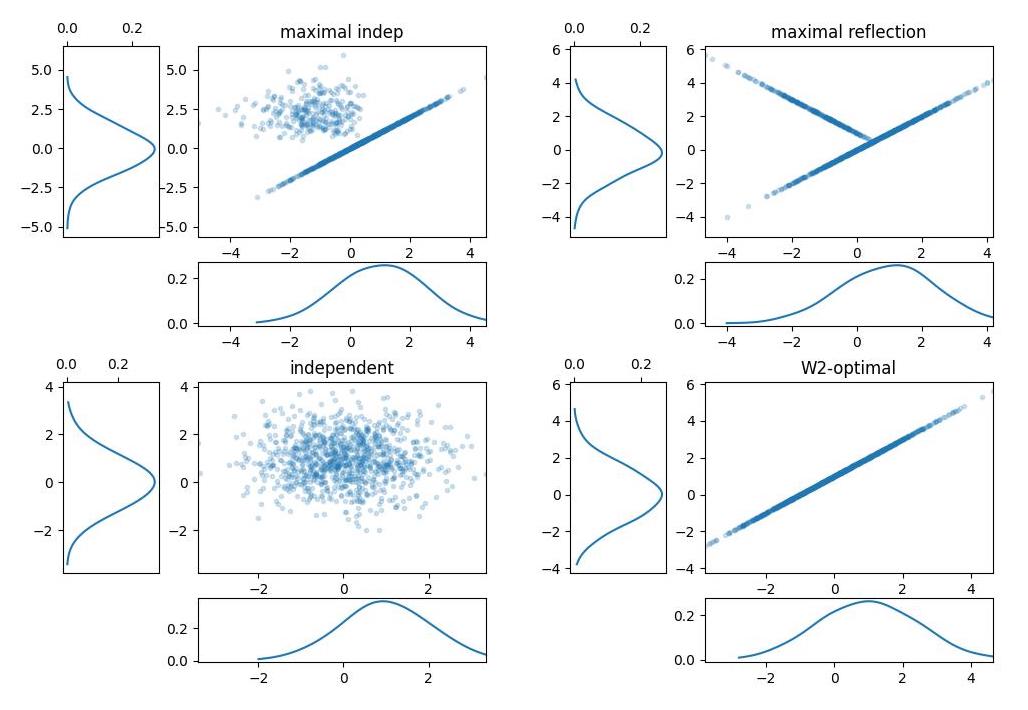
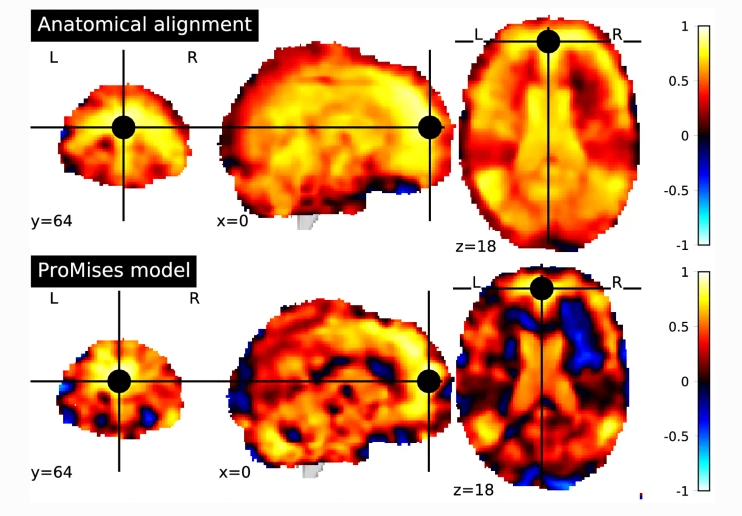
The Procrustes problem aims to match matrices using similarity transformations (i.e., rotation, reflection, translation, and scaling transformations) to minimize their Frobenius distance. It allows the comparison of matrices with dimensions defined in an arbitrary coordinate system. This method…
high-dimensional-data
Depth Quantile Functions
Gabriel Chandler and Wolfgang Polonik
/
2021-07-01
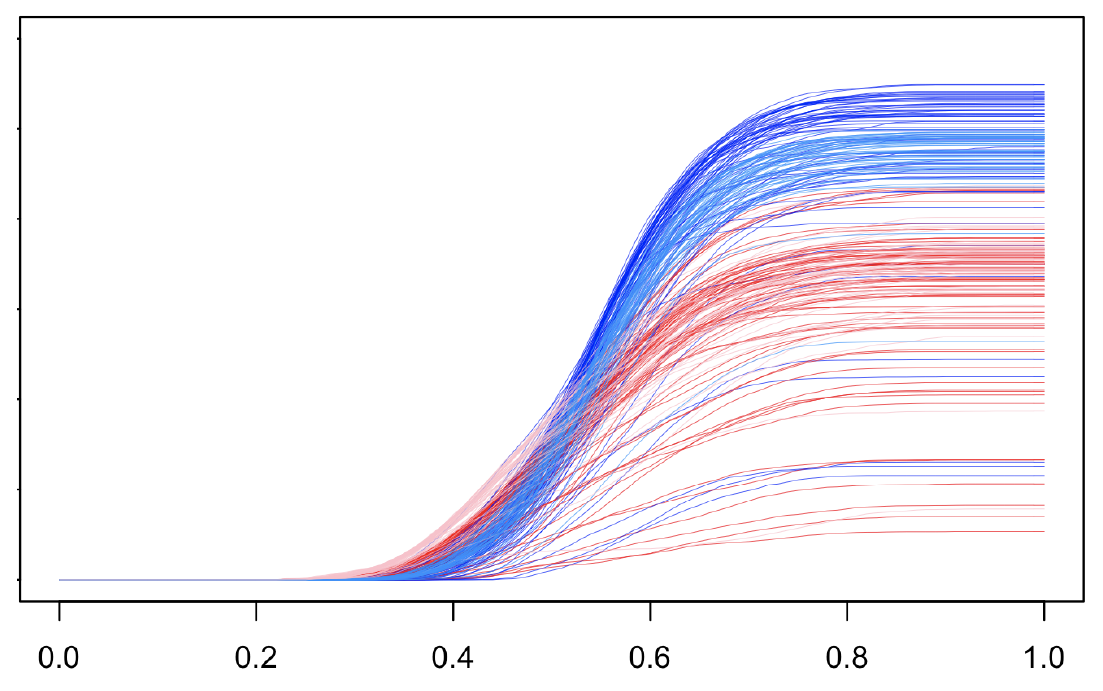
Figure 1: Depth quantile functions for the wine data (d=13), class 2 vs class 3. Blue curves correspond to between class comparisons, red/pink correspond to within class comparisons. A common technique in modern statistics is the so-called kernel trick, where data is mapped into a (usually)…
machine-learning
Higher Order Targeted Maximum Likelihood Estimation
Zeyi Wang and Mark van der Laan
/
2021-03-10
Summary We propose a higher order targeted maximum likelihood estimation (TMLE) that only relies on a sequentially and recursively defined set of data-adaptive fluctuations. Without the need to assume the often too stringent higher order pathwise differentiability, the method is practical for…
partial-least-squares
PLS for Big Data: A unified parallel algorithm for regularised group PLS
Pierre Lafaye de Micheaux, Benoit Liquet, Matt Sutton
/
2021-01-28
We look at the problem of learning latent structure between two blocks of data through the partial least squares (PLS) approach. These methods include approaches for supervised and unsupervised statistical learning. We review these methods and present approaches to decrease the computation time and…