Disclosure risk for microdata
Protection against disclosure is a legal and ethical obligation for agencies releasing microdata files for public use. Consider a microdata sample \({X}_n=(X_{1},\ldots,X_{n})\) of size \(n\) from a finite population of size \(\bar{n}=n+\lambda n\), with \(\lambda>0\), such that each sample record \(X_i\) contains two disjoint types of information: identifying categorical information and sensitive information. Identifying information consists of a set of categorical variables which might be matchable to known units of the population. A risk of disclosure results from the possibility that an intruder might succeed in identifying a microdata unit through such a matching, and hence be able to disclose sensitive information on this unit. To quantify the risk of disclosure, sample records \({X}_n\) are typically cross-classified according to identifying variables. That is, \({X}_n\) is partitioned in \(K_{n}\leq n\) cells, with \(Y_{j,n}\) being the number of \(X_{i}\)’s belonging to cell \(j\), for \(j=1,\ldots, K_{n}\), such that \(\sum_{1\leq j\leq K_{n}}Y_{j,n}=n\); we refer to the number of occurrences \(Y_{j,n}\) as the sample frequency of cell \(j\). We also indicate by \(Y_{j,\bar{n}}\) the same quantities referring to the entire population of size \(\bar{n}\). Then, a risk of disclosure arises from cells in which both sample frequencies and population frequencies are small. Of special interest are cells with frequency \(1\) (singletons or uniques) since, assuming no errors in the matching process or data sources, for these cells the match is guaranteed to be correct. This has motivated inferences on measures of disclosure risk that are suitable functionals of the number of uniques, the most common being the number \(\tau_{1}\) of sample uniques which are also population uniques, namely the following functional:
\[\tau_{1}=\sum_{j\geq 1}\mathbf{1}_{\{Y_{j,n}=1\}}\mathbf{1}_{\{Y_{j,\bar{n}}=1\}},\]
where \(\mathbf{1}\) denotes the indicator function.
We first introduce a class of nonparametric estimators of \(\tau_{1}\), we then show that they provably estimate \(\tau_{1}\) all of the way up to the sampling fraction \((\lambda+1)^{-1}\propto (\log n)^{-1}\), with vanishing normalized mean squared error (NMSE) for large sample size \(n\). More importantly we prove that \((\lambda+1)^{-1}\propto (\log n)^{-1}\) is the smallest possible sampling fraction for consistently estimating \(\tau_{1}\), thus the estimators’ NMSE is near optimal. Our paper also provides a rigorous answer to an open question raised by Skinner and Elliot (2002) about the feasibility of nonparametric estimation of \(\tau_{1}\) and for a sampling fraction \((\lambda+1)^{-1}<1/2\).
Nonparametric estimation of \(\tau_{1}\)
A nonparametric estimator for \(\tau_1\) may be simply deduced by comparing expectations. Indeed, under a suitable Poisson abundance model for the cells’ proportions, it easy to see that
\[\label{eq:comparingE} \mathbb{E} [\tau_1] = \sum_{i \geq 0}(-1)^i \lambda^i (i+1) \mathbb{E} [Z_{i+1, n}],\]
where \(Z_{i,n}\) denotes the number of cells with frequency \(i\) out of the sample \({X}_n\). Thus, according to identity , we can define the following estimator of \(\tau_1\):
\[\label{eq:estimator<1} \hat{\tau}_{1}=\sum_{i \geq 0} (-1)^{i} (i+1)\lambda^{i}Z_{i+1}.\]
By construction, the estimator is unbiased and it admits a natural interpretation as a nonparametric empirical Bayes estimator in the sense of Robbins(1956). The use of estimator is legitimated under the assumption \(\lambda<1\). For \(\lambda \geq 1\) it becomes useless, because of its high variance due to the exponential growth of the coefficients \(\lambda^i\). Unfortunately, the assumption \(\lambda < 1\) is unrealistic in the context of disclosure risk assessment, where the size \(\lambda n\) of the unobserved population is typically much bigger than the size \(n\) of the observed sample. Thus the estimator requires an adjustment via suitable smoothing techniques, along similar lines as Orlitsky et al. (2016) in the context of the nonparametric estimation of the number of unseen species. We propose a smoothed version of \(\hat{\tau}_{1}\) by truncating the series at an independent random location \(L\), and then averaging over the distribution of \(L\), i.e.,
\[\begin{aligned} \label{eq:estimator>1} \hat{\tau}_{1}^L&= {\mathbb{E}}_L \left[ \sum_{i =1}^L (-1)^{i} (i+1) \lambda^i Z_{i+1,n}\right],\end{aligned}\]
where \(L\) is supposed to be a Poisson or a Binomial random variable, but other choices are possible.
Main results
We have evaluated the performance of the estimator \(\hat{\tau}_{1}^L\) in terms of the normalized mean squared error (NMSE). The NMSE is the mean squared error (MSE) of the estimator normalized by the maximum value of \(\tau_{1}\) (which is exactly \(n\)). Thus, the performance of an estimator is evaluated in terms of the rate of convergence to \(0\) of the NMSE as \(n \to +\infty\). See also Orlitsky et al. (2016) for a definition of NMSE. In our paper we have proved that \(\hat{\tau}_{1}^L\) provably estimate \(\tau_{1}\) all of the way up to the sampling fraction \((\lambda+1)^{-1}\propto (\log n)^{-1}\) of the population, with vanishing normalized mean-square error (NMSE) as \(n\) becomes large. Then, by relying on recent techniques developed in Wu and Yang (2019) in the context of nonparametric estimation of the support size of discrete distributions, we are also able to provide us with a lower bound for the NMSE of any estimator of the disclosure risk \(\tau_1\). The lower bound we find has an important implication: without imposing any parametric assumption on the model, one can estimate \(\tau_1\) with vanishing NMSE all the way up to \(\lambda \propto \log n\). It is then impossible to determine an estimator having provable guarantees, in terms of vanishing NMSE, when \(\lambda = \lambda (n)\) goes to \(+\infty\) much faster than \(\log (n)\), as a function of \(n\). Moreover it follows that the ``limit of predictability” of \(\hat{\tau}_{1}^L\) in is near optimal, because it matches (asymptotically) with its maximum possible value \(\lambda \propto \log (n)\), under suitable choices of the smoothing distribution \(L\).
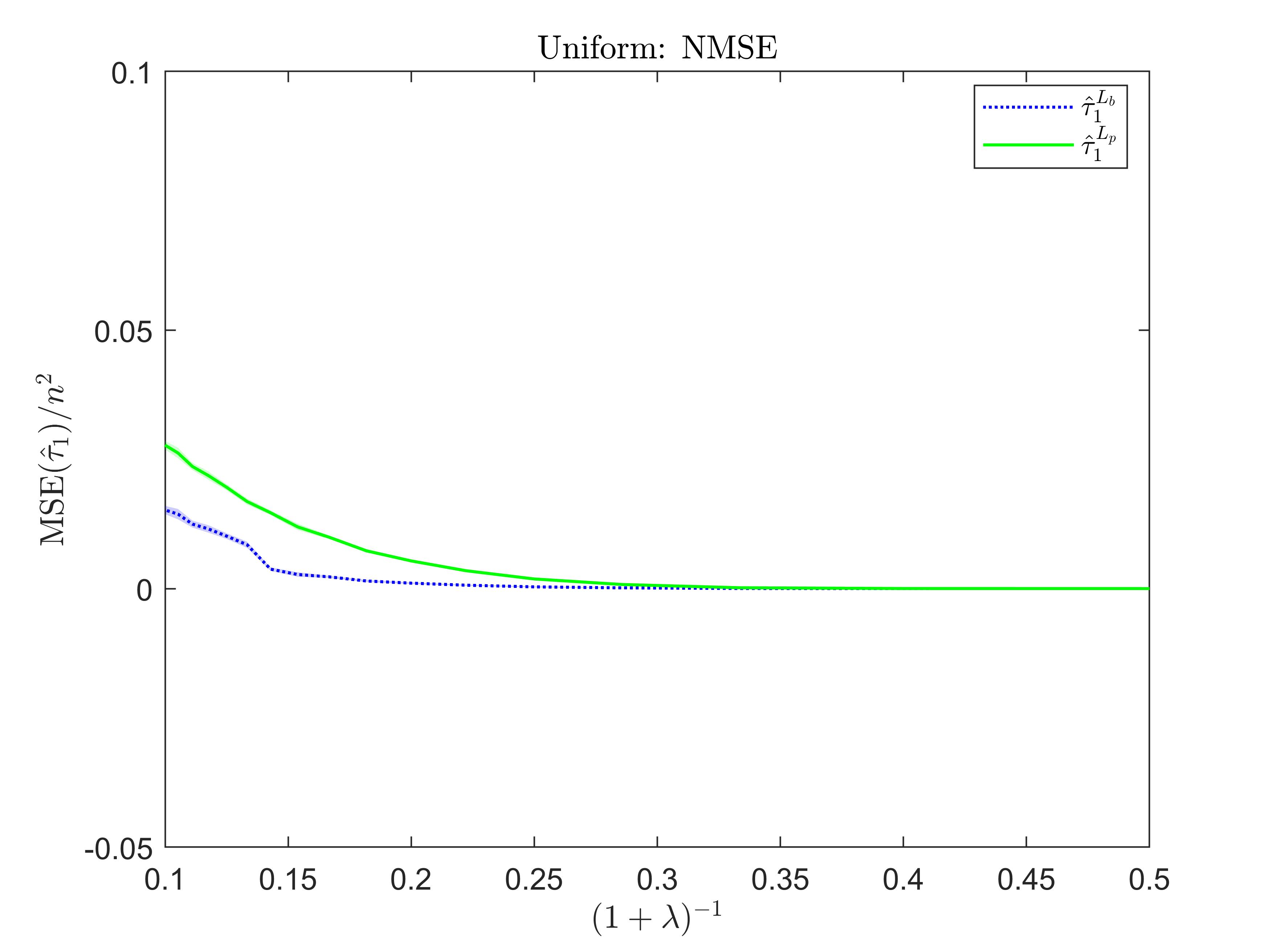
Figure 1: The normalized mean squared error as a function of the sampling fraction \((1+\lambda)^{-1}\) when the cell’s probabilities are uniform distributed. Each curve corresponds to a different estimator of \(\tau_1\): i) the nonparametric estimator with Binomial smoothing \(\hat{\tau}_1^{L_b}\); ii) the nonparametric estimator with Poisson smoothing \(\hat{\tau}_1^{L_p}\).
The performance of our nonparametric approach is shown in Figure 1.
In order to do that, we generated a collection of synthetic tables with \(C\) cells, where \(C=3 \cdot 10^6\). The population size is fixed to \(\bar{n}=10^{6}\), and we evaluated the NMSE for different values of the sample size \(n=\bar{n}(\lambda+1)^{-1}\). The underlying true cells’ probabilities are generated according to a uniform distribution over the total number of cells. The figure shows how the NMSE varies as a function of the sampling fraction \((1+\lambda)^{-1}\), for the estimator \(\hat{\tau}_1^L\), under a Poisson and a Binomial smoothing. All the estimates are averaged over 100 iterations. The sampling fractions considered in our simulation study are above the limiting threshold \((\log n)^{-1}\) and the better performance seems to be achieved under the Binomial smoothing.
Authors
 Federico Camerlenghi is an Assistant Professor of Statistics at the
University of Milano-Bicocca (Italy).
Federico Camerlenghi is an Assistant Professor of Statistics at the
University of Milano-Bicocca (Italy).
 Stefano Favaro is a Full Professor of Statistics at the University
of Torino (Italy), and he is also a Carlo Alberto Chair at Collegio
Carlo Alberto (Torino, Italy).
Stefano Favaro is a Full Professor of Statistics at the University
of Torino (Italy), and he is also a Carlo Alberto Chair at Collegio
Carlo Alberto (Torino, Italy).
 Zacharie Naulet is a Maître de Conférence at the Department of
Mathematics of Université Paris-Sud (France).
Zacharie Naulet is a Maître de Conférence at the Department of
Mathematics of Université Paris-Sud (France).
 Francesca Panero is finishing her Ph.D. in Statistics at the
University of Oxford (UK).
Francesca Panero is finishing her Ph.D. in Statistics at the
University of Oxford (UK).
References
Good, I.J. and Toulmin, G.H. (1956). The number of new species, and the increase in population coverage, when a sample is increased. Biometrika 43, 45–63.
Orlitsky, A., Suresh, A.T. and Wu, Y. (2017). Optimal prediction of the number of unseen species. Proc. Natl. Acad. Sci. USA 113, 13283–13288.
Robbins, H. (1956). An empirical Bayes approach to statistics. Proc. 3rd Berkeley Symp.,1, 157–163.
Skinner, C.J. and Elliot, M.J. (2002). A measure of disclosure risk for microdata. J. Roy. Statist. Soc. B 64, 855–867.
Skinner, C., Marsh, C., Openshaw, S. and Wymer, C. (1994). Disclosure control for census microdata. J. Off. Stat. 10, 31–51.
Skinner, and Shlomo, N. (2008). Assessing identification risk in survey microdata using log-linear models. J. Amer. Statist. Assoc. 103, 989–1001.
Wu, Y. and Yang, P. (2019). Chebyshev polynomials, moment matching, and optimal estimation of the unseen. Ann. Statist., 47, 857–883.