I’ve kindly been invited to share a few words about a recent paper my colleagues and I published in Bayesian Analysis: “Bayesian Regression Tree Models for Causal Inference: Regularization, Confounding, and Heterogeneous Effects”. In that paper, we motivate and describe a method that we call Bayesian causal forests (BCF), which is now implemented in an R package called bcf.
The goal of this post is to work through a simple toy example to illustrate the strengths of BCF. Through this example I hope to explain what I mean when I say that BCF is “machine learning for causal inference that works”.
Problem setting
Suppose we want to estimate a possibly heterogeneous treatment effect of a binary treatment variable. This means, for example, that we want to know if a new drug reduces the duration of a headache and we think maybe the drug works better for some people and worse for other people. In addition to the question “how well (if at all) does the drug work?” we also want to know if the people for whom it works better can be characterized in terms of observable attributes, perhaps age, gender, or ethnicity. People either get the drug or not (we do not consider differing doses). Unfortunately, who gets the drug is not randomized, which complicates things. For example, if people who take the drug happen to be the ones with longer duration headaches (on average), that could skew our impression of how effective the drug is.
Although we do not have a randomized sample, let’s assume we are lucky enough to have the next best thing, which is that we observe all the attributes of each patient that affect how likely they are to have taken the drug. It is well known that access to these factors allows us to correctly estimate the treatment effect by turning the causal inference problem into a regression problem (aka supervised learning). Specifically, in that case the treatment effect can be expressed as
\[ \tau(x_i) = \mbox{E}(Y \mid Z = 1, X = x_i) - \mbox{E}(Y \mid Z = 0, X = x_i) \]
where \(Y\) is the response or outcome variable (the duration of headache), \(Z\) is the treatment assignment (did the patient take the drug or not), and \(x_i\) is a vector of attributes of patient \(i\). This difference is called the conditional average treatment effect, or CATE; “conditional” refers to the fixed \(x_i\) vector, “average” refers to the expectation over \(Y\), and “treatment effect” refers to the difference between to treated (\(Z = 1\)) and untreated (\(Z = 0\)), or control, groups. If this quantity differs for distinct \(x_i\), we say that there are “heterogeneous” effects.
The good news is that we have many methods that efficiently estimate conditional expectations in the difference above. The bad news, which wasn’t widely appreciated even just a few years ago, is that those methods don’t work as well as they should in terms of estimating the CATEs. Let’s take a look at why that is.
Simple machine learning CATE estimators are high-variance
A natural thing to do when faced with estimating two conditional expectations is simply to estimate them separately, training two separate machine learning models using the control group data and the treated group data individually. With enough data, this approach works just fine, but if the conditional expectation functions underlying the data are complicated relative to the available sample size, this approach can be highly unstable. This instability arises because fitting the two functions completely separately provides no control, or regularization, over the implied fluctuations in the CATE (the difference between the two conditional mean functions).
It is well-known that for good nonparametric function estimation, effective regularization is necessary to prevent overfitting; this is the main insight from decades of supervised machine learning. But in causal inference, the goal is not estimating the conditional expectations themselves, but rather their difference. Without penalizing complexity of \(\tau(x)\) itself, one runs the risk of overfitting the treatment effects! And that’s exactly what happens in our example below.
This excessive variability has a fairly simple fix, which is to regularize the difference the same way you would penalize the complexity of an unknown function: \[ \mbox{min}_{f_0, f_1}\;\;\;\; \frac{1}{n_0} \sum_{i: z_i = 0}||y_i - f_0(x_i)||^2_2 + \frac{1}{n_1} \sum_{i: z_i = 1} ||y_i - f_1(x_i)||^2_2 + \lambda_0||f_0|| + \lambda_1||f_1|| + \lambda_{\tau}||f_1 - f_0|| \]
where \(\lambda_0\), \(\lambda_1\), and \(\lambda_{\tau}\) are regularization tuning parameters and \(||\cdot||\) denotes a measure of the complexity of a function.
A new problem: regularization induced confounding (RIC)
Incorporating the \(||f_1 - f_0||\) penalty solves one problem but introduces a new, subtler, one. Adding a constant to \(f_1\) does not increase the complexity of \(f_1\) or \(f_1 - f_0\), but doing so may allow the complexity of \(f_0\) to be decreased without worsening the fit to the data (the first two terms of the objective function above). In practical terms, this means that the new regularization term we just introduced might have the unintended effect of inflating our treatment effect estimates!
When specifically might this happen? It can happen when the true \(f_0\) is quite complex and the probability of being treated is a monotone function of \(f_0\):
\[ \mbox{Pr}(Z = 1 \mid x) = \pi(x) = \pi(f_0(x)) \]
and \(\frac{\partial \pi}{\partial f_0}\) never changes sign. Under this assumption, the treated observations in our data would tend to have higher outcome values, which our model could chalk up to a treatment effect without needing to learn the complicated pattern of \(f_0\) because it is implicitly encoded in the treatment assignment variable, \(z\).
Is this situation plausible? Well, in our headache drug example, it would mean that people are more likely to take a drug if they are likely to have a very long lasting headache if they didn’t take it. If people (or their doctors) expect the drug to help, this assumption makes total sense! We call these sorts of situations targeted selection.
Solving the RIC issue turns out to be pretty easy, too: simply add an estimate of \(\pi(x)\) as a control variable. This allows the model to learn the true \(f_0\) with a simple representation based on the extra feature, in the event that targeted selection is occurring.
Example
Now let’s work through a simple example illustrating these ideas. We will consider a nonlinear but elementary conditional expectation function and simulate our treatment assignment variable according to targeted selection. \[ \begin{split} \tau(x) &= -1 + x\\ f_0(x) &= 2 \{\sin(v x) + 1\}\\ f_1(x) &= f_0(x) + \tau(x) = -1 + x + 2 \{\sin(v x) + 1\}\\ \pi(x) &= f_0(x)/5\\ y_i &= f_0(x_i) + \tau(x_i) + \sigma\epsilon_i \end{split} \] where \(\epsilon_i\) are independent and identically distributed standard normal random variables. Our sample consists of \(n\) evenly spaced observations \(x\) on the unit interval. This data generating process (DGP) guarantees that the probability of treatment ranges between 0.1 to 0.9. The parameter \(v\) governs the “complexity” of \(f_0\) and \(f_1\), while the parameter \(\sigma\) governs the statistical difficulty of the learning problem.
# set sample size and set control variable values
n = 1000
x = seq(0,1,length.out = n)
# set the problem difficulty
v = 30
kappa = 2
# define functions
mu = function(x){2*(sin(v*x)+1)}
tau = function(x){-1 + x}
pi = function(x){mu(x)/5 + 0.1}
# draw treatment assignment
z = rbinom(n,1,pi(x))
# draw outcome
f_xz = mu(x) + tau(x)*z
sigma = kappa*sd(f_xz)
y = f_xz + sigma*rnorm(n)
# calculate the true average treatment effect (ATE)
print(mean(tau(x)))## [1] -0.5# calculate the naive estimate of the ATE
print(mean(y[z==1]) - mean(y[z==0]))## [1] 0.9889149Observe that the naive estimate is way off from the truth due to strong confounding.
Next, let’s use the separate regressions approach to estimating the treatment effect. To do this we will use the R package XBART, based on another paper of mine. It can be downloaded and installed from here (but must be compiled from source).
fit.f1 = XBART(y[z==1],x[z==1],x,
num_sweeps = sweeps, burnin = b, num_trees = 20,
tau = var(y[z==1])/20)
yhat1 = rowMeans(fit.f1$yhats_test[,(b+1):sweeps])
fit.f0 = XBART(y[z==0],x[z==0],x,
num_sweeps = sweeps, burnin = b, num_trees = 20,
tau = var(y[z==0])/20)
yhat0 = rowMeans(fit.f0$yhats_test[,(b+1):sweeps])
tau.est1 <- yhat1 - yhat0Next, let’s explicitly regularize the treatment effect. We will do this using the R package XBCF, which can be downloaded here.
xbcf_fit = XBCF(scale(y), x, x, z,
num_sweeps = sweeps, burnin = b, Nmin = 1, verbose = FALSE,
num_cutpoints = 20, max_depth = 250,
num_trees_pr = 20, tau_pr = tau1,
num_trees_trt = 20, alpha_trt = 0.7, beta_trt = 2, tau_trt = tau2)## Warning in if (class(y) != "matrix") {: the condition has length > 1 and only
## the first element will be usedtau.est2 = getTaus(xbcf_fit)Finally, let’s do it the right way and also incorporate the estimated propensity scores. First, we estimate them. Here, we again use XBART, but your favorite classification algorithm would be okay, too.
fitz = XBART.multinomial(y = z, num_class = 2, X = x, Xtest = x,
num_trees = 20, num_sweeps = sweeps, max_depth=250,
Nmin=6, num_cutpoints=50, tau_a = 2, tau_b = 1,
burnin = b, verbose = FALSE, parallel = TRUE,
sample_weights_flag = TRUE, weight = 5,update_tau = TRUE)
pihat = apply(fitz$yhats_test[(b+1):sweeps,,], c(2, 3), mean)[,2]With those estimates in hand, we then run XBCF again, this time including the propensity score as an extra feature.
xbcf_fit.ps = XBCF(scale(y), cbind(pihat,x), x, z,
num_sweeps = sweeps, burnin = b, Nmin = 1, verbose = FALSE,
num_cutpoints = 20, max_depth = 250,
num_trees_pr = 20, tau_pr = tau1,
num_trees_trt = 20, alpha_trt = 0.7, beta_trt = 2, tau_trt = tau2)## Warning in if (class(X) != "matrix") {: the condition has length > 1 and only
## the first element will be used## Warning in if (class(y) != "matrix") {: the condition has length > 1 and only
## the first element will be usedtau.est3 = getTaus(xbcf_fit.ps)And now we can plot the results against the truth and compute the root mean squared estimation error of the CATEs.
plot(x,tau(x),type='l',ylim=c(-1.5,1.5),col='red',lty=2,lwd=2,bty='n',ylab=expression(tau))
lines(x,tau.est1,col='lightgray',lwd=3)
lines(x,tau.est2,col='blue',lwd=3)
lines(x,tau.est3,col='green',lwd=3)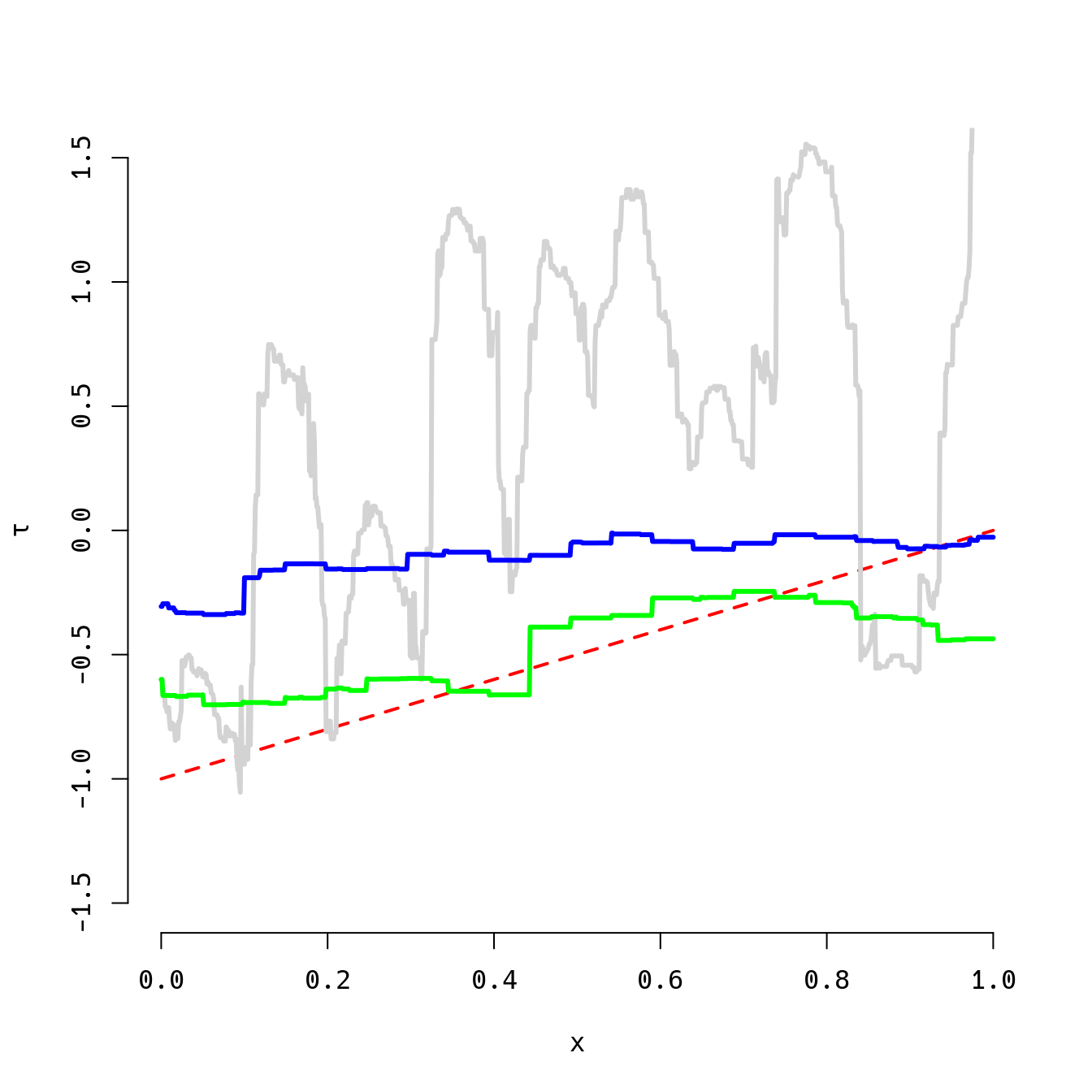
rmse1 = sqrt(mean((tau(x)-tau.est1)^2))
rmse2 = sqrt(mean((tau(x)-tau.est2)^2))
rmse3 = sqrt(mean((tau(x)-tau.est3)^2))
print(round(c(rmse1,rmse2,rmse3),2))## [1] 1.15 0.45 0.18The pattern here is bad (gray), better (blue), best (green) from left to right. The true heterogeneous treatment effect function is depicted by the dashed red line. The third approach (the approach we advocate for in the BCF paper) is not always better, but it is most of the time, sometimes by a very large margin. Try it out yourself, varying the sample size (\(n\)) and the two difficulty parameters (\(v\) and \(\sigma\)).
Conclusions
There are now many researchers working at the intersection of machine learning and causal inference. What distinguishes our work is a focus on building tools that work in practice, which requires understanding the role of regularization in causal inference and engineering methods that impose effective regularization schemes that have been calibrated to the kind of data we expect to encounter in common applications.